-
15th April 2016 11:43 PM
#1
آيا اين پست براي شما سودمند بود؟
بله |
خیر
آموزش شبکه کانولوشن بخش اول
بسم الله الرحمن الرحیم
خب میخوام انشاالله اگر خدا بخواد به مرور بخش هایی از اسناد و داکیومنتهایی که قبلا خودم نوشتم رو تو سایت قرار بدم . قرار بود این کار رو بعد از تموم شدن دفاعم بزارم ولی خب این قضیه داره برای من خیلی کش پیدا میکنه (کاغذ بازی دانشگاه و الان وزارت خارجه! و تایید مدارک استاد راهنمام و… ) و نمیدونم آخرش چی میشه . توکل بخدا . برای همین تصمیم گرفتم زودتر کارو پیش ببرم . این مطالبی که میزارم نوشته های خودم هست که قراره بخشی از مستندات پایان نامم باشه و ماه ها قبل نوشتمشون ولی هنوز کار دارن و ویرایش نشدن برای همین هر بار یه بخشی رو قرار میدم. تو بخش اول در مورد کلیات شبکه های کانولوشنی صحبت میکنم و انشاالله طی پست های بعدی وارد جزییات بیشتر میشم.(مطالبی که اینجا اومده و بعدا انشاالله میاد تمام آموزشهای شبکه عصبی کانولوشن دانشگاه استنفورد رو پوشش میده و علاوه بر اون توضیحات تکمیلی و موارد بیشتری هم در بر داره تا مطلب بهتر جا بیوفته.
شبکه های کانولوشن :
شبکه های عصبی کانولوشن تا حد بسیار زیادی شبیه شبکه های عصبی مصنوعی هستند که در بخش قبلی در مورد آنها توضیح داده شد. این نوع شبکه ها متشکل از نورونهایی با وزنها و بایاسهای قابل یادگیری (تنظیم) هستند.[۱] هر نورون تعدادی ورودی دریافت کرده و سپس حاصل ضرب وزنها در ورودی ها را محاسبه کرده و در انتها با استفاده از یک یک تابع تبدیل(فعال سازی) غیرخطی نتیجه ای را ارائه دهد. کل شبکه همچنان یک تابع امتیاز (Score function) مشتق پذیر(differentiable) را ارائه میکند, که در یک طرف آن پیکسل های خام تصویر ورودی و در طرف دیگر آن امتیازات مربوط به هر دسته قرار دارد. این نوع شبکه ها هنوز یک تابع هزینه (Loss function) (مثل SVM,Softmax) در لایه آخر (تماما مرتبط یا fully connected) دارند و تمامی نکات مطرحی در مورد شبکه های عصبی معمولی در اینجا هم صادق است. با توجه به مطالب گفته شده ,تفاوت شبکه عصبی کانولوشن با شبکه عصبی مصنوعی در چه چیزی میتواند باشد ؟ معماری های شبکه های عصبی کانولوشن بصورت صریح فرض میکنند که ورودی های آنها تصاویر هستند , با این فرض ما میتوانیم ویژگی های مشخصی را درون معماری تعبیه (encode) کنیم .با این عمل تابع پیشرو (forward function) را میتوان بصورت بهینه تر پیاده سازی کرد و همینطور با این کار میزان پارامترهای شبکه نیز بشدت کاهش پیدا میکند.
خلاصه معماری
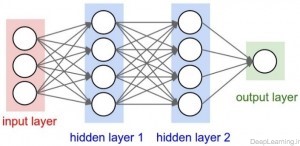
همانطور که ما میدانیم, شبکه های عصبی یک ورودی دریافت میکنند (در قالب یک بردار ) و سپس آنرا از تعدادی لایه مخفی (Hidden layer) عبور میدهند. و نهایتا یک خروجی که نتیجه پردازش لایه های مخفی است در لایه خروجی شبکه ظاهر میشود. هر لایه مخفی از تعدادی نورون تشکیل شده که این نورون ها به تمام نورون های لایه قبل از خود متصل میشوند. نورونهای هر لایه بصورت مستقل عمل کرده و هیچ ارتباطی با یکدیگر ندارند. آخرین لایه تماما متصل (fully connected layer) به لایه خروجی (output layer) معروف است و معمولا نقش نمایش دهنده امتیاز هر دسته(class) را ایفا میکند. شبکه های عصبی معمولی برای تصاویر معمول(full images) بخوبی مقیاس پذیر نیستند. بعنوان مثال تصاویر موجود در دیتاست CIFAR-10 [2] اندازه ای برابر با ۳۲ x 32 x 3 دارند (۳۲ پیکسل عرض, ۳۲ پیکسل ارتفاع و ۳ کانال رنگ ) . بنابر این یک نورون با اتصال کامل (fully connected) در لایه مخفی اول یک شبکه عصبی معمولی ۳۲ x 32 x 3 = 3072 وزن خواهد داشت . این مقدار شاید در نظر اول مقدار قابل توجهی بنظر نیاید اما بطور واضح مشخص است که این معماری تماما مرتبط قابل استفاده برای تصاویر بزرگتر نخواهد بود. برای مثال یک تصویر با اندازه متعارف تر مثل ۲۰۰ x 200 x 3 باعث میشود که یک نورون ۲۰۰ x 200 x 3 = 120,000 وزن داشته باشد!. علاوه بر این ما قطعا خواهان تعداد بیشتری از این نورون ها خواهیم بود , پس تعداد پارامترها بسرعت افزایش پیدا میکند . مشخص است این اتصال کامل (Full connectivity) باعث اتلاف (wasteful) بوده و تعداد بسیار زیاد پارامترها هم بسرعت باعث overfitting خواهد شد.
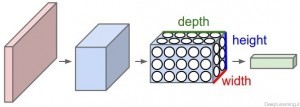
توده های سه بعدی از نورونها!(۳d volumes of neurons):
شبکه های عصبی کانولوشن از این واقعیت که ورودی شامل تصاویر است استفاده کرده و معماری شبکه را به روش معقولی محدود کردند. بطور خاص, برخلاف یک شبکه عصبی معمولی, لایه های یک شبکه عصبی کانولوشن (به اختصار ConvNet) شامل نورونهایی است که در سه بعد عرض, ارتفاع و عمق قرار گرفته اند(مرتب شده اند).(دقت کنید که کلمه عمق در اینجا اشاره به بُعد سوم یک توده فعال سازی (activation volume)[3] دارد و به معنای عمق یک شبکه عصبی کامل که به معنای تعداد لایه های موجود در آن است نمیباشد.). بعنوان یک مثال, تصاویر ورودی از دیتاست CIFAR-10 ,هر کدام یک توده ورودی حاوی مقادیر فعال سازی[۴] an Input volume of activations)) هستند که دارای ابعاد ۳۲ x 32 x 3 (عرض, ارتفاع و عمق ) هستند. همانطور که جلوتر خواهیم دید, هر نورون در هر لایه بجای اتصال با تمام نورون ها در لایه قبل تنها به ناحیه کوچکی از لایه قبل از خود متصل است. علاوه بر آن, لایه خروجی نهایی برای تصاویر رقابت CIFAR-10 دارای ۱x1x10 بُعد خواهد بود., چرا که همگام با رسیدن به انتهای معماری شبکه ConvNet ما اندازه تصویر را کاهش میدهیم بگونه ای که در انتها تصویر کامل ورودی ما به یک بردار حاوی امتیاز دسته ها (کلاسها) کاهش پیدا میکند و ما با یک بردار که حاوی امتیاز هر دسته است مواجه خواهیم بود. این امتیازات در امتداد بعد عمق(depth dimension) مرتب شده اند. نمایشی از این عمل را در زیر میتوانید مشاهده کنید : همانطور که در تصویر بالا میبینید در هر لایه, یک شبکه عصبی کانولوشن (ConvNet) نورون های خود را در ۳ بعد مرتب میکند (عرض , ارتفاع و عمق ) هر لایه یک شبکه ConvNet ورودی را در قالب یک توده سه بعدی به یک توده سه بعدی خروجی از مقادیر فعال سازی نورونها تبدیل میکند. در این مثال لایه ورودی قرمز رنگ حاوی تصویر است(مقادیر پیکسل های تصویر) بنابر این عرض و ارتفاع آن ابعاد تصویر خواهند بود و عمق آن هم برابر با ۳ خواهد بود (کانال های قرمز, سبز و آبی مربوط به تصویر) یک شبکه ConvNet از چند لایه تشکیل میشود و هر لایه شیوه کار ساده ای دارد. که در آن یک توده سه بعدی ورودی دریافت کرده و آن را با استفاده از توابعی مشتق پذیر (differentiable function) که ممکن است با پارامتر یا بدون پارامتر باشند به یک توده سه بعدی خروجی تبدیل میکند.
[۱] از آنجایی که مقادیر مربوط به این پارامترها ی مراحلی بصورت خودکار تنظیم میشود, ما از ان به یادگیری یاد میکنیم , چرا که شبکه عصبی گام بگام با یادگیری این پارامترها قادر به انجام وظیفه شناسایی محول شده به آن میشود.
[۲] یکی از دیتاست های معروف که جهت رقابتهای جهانی پردازش تصویر مورد استفاده قرار میگیرد. این دیتاست شامل ۶۰ هزار تصویر رنگی با اندازه ۳۲×۳۲ پیکسل در ۱۰ دسته مختلف است. (CIFAR-10 and CIFAR-100 datasets, 2012)
[۳] توده فعال سازی یا Activation volume به یک توده سه بعدی حاوی مقادیر عددی گفته میشود که بعنوان ورودی به تابع فعال سازی ارسال میشوند, برای همین به آنها توده فعال سازی گفته میشود. مقادیر موجود در این توده ها ممکن است مقادیر متناظر به پیکسلهای خام تصاویر باشند (توده فعال سازی ورودی) و یا نتیجه پردازش های انجام شده تا لایه خاصی در شبکه باشند (بعنوان مثال توده فعال سازی در لایه دوم یعنی مقادیر عددی در لایه دوم که نتیجه عملیاتهای لایه های قبل تا لایه فعلی است (ضرب وزنها در خروجی حاصل از لایه قبل و…)
[۴] در اینجا مقادیر فعال سازی چیزی جز مقادیر مربوط به پیکسل های خام تصاویر ورودی نیستند.
لایه های مورد نیاز برای ایجاد یک شبکه ConvNet
همانطور که در بالا اشاره کردیم, هر لایه شبکه کانولوشن یک توده فعال سازی را از طریق یک تابع مشتق پذیر به توده فعال سازی دیگر تبدیل میکند. ما از سه نوع اصلی لایه ها برای ساخت یک معماری شبکه کانولوشن استفاده میکنیم . این لایه ها عبارتند از : لایه کانولوشن, لایه Pooling و لایه تماما متصل (Fully connected layer) که دقیقا همانند همان که در شبکه های عصبی معمولی میبینیم است . ما این لایه ها را روی هم قرار میدهیم تا یک معماری کامل از شبکه کانولوشن ایجاد کنیم .
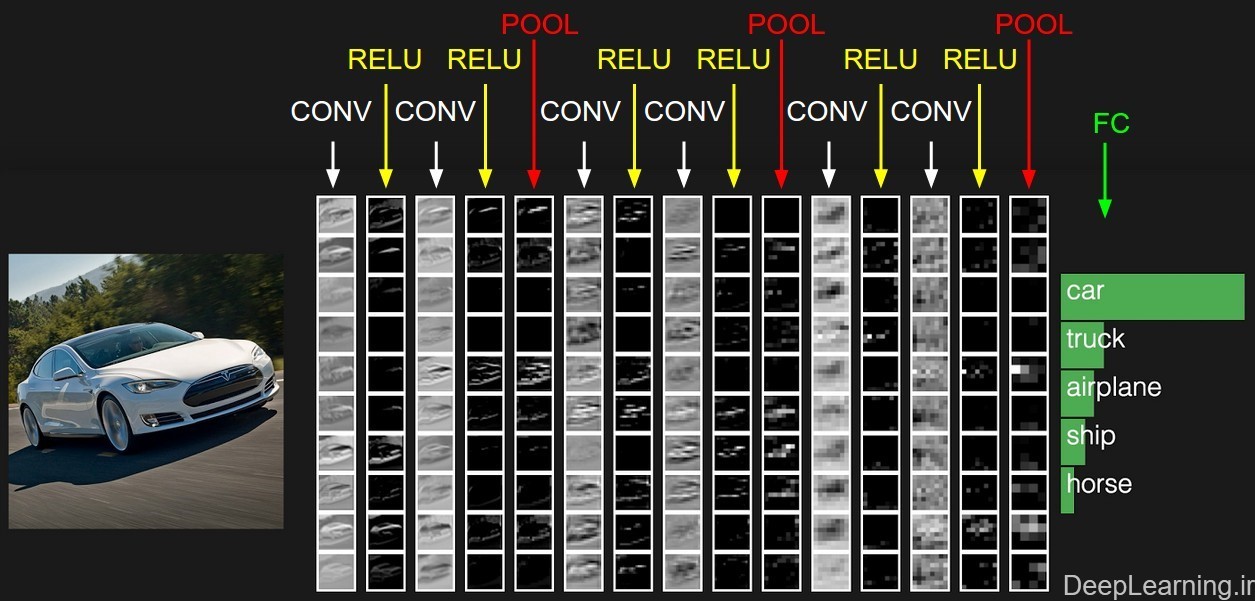
برای روشن تر شدن بیشتر مباحث بالا یک شبکه کانولوشن ساده برای دسته بندی دیتاست CIFAR-10 ایجاد میکنیم . برای اینکار ما میتوانیم یک معماری با لایه های لایه ورودی , لایه کانولوشن, لایه RELU , لایه POOL , لایه FC داشته باشیم .
لایه ورودی (Input layer) شامل مقادیر پیکسل های خام تصویر ورودی ما هستند . یعنی در اینجا ما یک تصویر با عرض ۳۲ , ارتفاع ۳۲ و ۳ کانال رنگ قرمز,سبز , آبی خواهیم داشت.
لایه کانولوشن (CONV layer) این لایه خروجی نورونهایی که به نواحی محلی در ورودی متصل هستند را محاسبه میکند. عمل محاسبه هم از طریق ضرب نقطه ای بین وزن های هر نورون و ناحیه ای که آنها به آن(توده فعال سازی ورودی) متصل هستند صورت میگیرد. نتیجه این عمل یک توده با اندازه ۳۲ x 32 x 12 میشود.
لایه RELU بر روی تک تک نورون ها یک تابع فعال سازی مثل max(0,x) (که آستانه گذاری را بر روی ۰ انجام میدهد یعنی مقادیر منفی را صفر در نظر میگیرد) را اعمال میکند. این کار تغییری در اندازه توده از مرحله قبل نمیدهد بنابر این نتیجه همچنان یک توده با اندازه ۳۲ x 32 x 12 خواهد بود .
لایه Pooling عملیات downsampling را در امتداد ابعاد مکانی (عرض و ارتفاع) انجام میدهد که نتیجه این کار یک توده با اندازه ۱۶ x 16 x 12 خواهد بود . همانطور که دقت کردید در لایه pooling ما ابعاد توده ورودی (تصویر) را کاهش میدهیم.و در اصل از طریق عملیات این لایه است که در انتهای شبکه کانولوشن ما به یک بردار امتیاز دست پیدا میکنیم .
لایه FC یا تماما مرتبط وظیفه محاسبه امتیاز دسته ها (class) را دارد. نتیجه کار این لایه یک توده با اندازه ۱x1x10 است که هر کدام از این ۱۰ عدد نمایانگر یک امتیاز برای یک دسته بخصوص (مثل یکی از ۱۰ دسته تصویر موجود در دیتاست CIFAR-10 ) است. مثل شبکه های عصبی معمولی و همانطور که از اسم این لایه بر می آید هر نورون در این شبکه با تمام نورون ها در توده قبل از خود ارتباط دارد.
با این روش, شبکه کانولوشن مقادیر پیکسل های خام تصویر اصلی را لایه به لایه به امتیاز دسته ها در انتهای شبکه تبدیل میکند.. دقت کنید که بعضی از لایه ها پارامتر داشته و بعضی دیگر فاقد پارامتر اند. بطور خاص لایه های Conv/FC لایه هایی هستند که تبدیلاتی را انجام میدهند که نه تنها تابعی از فعال سازی ها(مقادیر موجود) در توده ورودی اند بلکه تابع پارامترهایی نظیر وزن و بایاس نورون ها هم هستند .از طرف دیگر لایه های RELU/POOL تنها یک تابع ثابت را پیاده سازی میکنند. پارامترهای موجود در لایه های Conv/FC توسط روش gradient descent آموزش میبینند تا امتیازات دسته ها (class)یی که شبکه کانولوشن حساب میکند با برچسب های هر تصویر در مجموعه آموزشی سازگار باشد.(همخوانی داشته باشد).
بطور خلاصه :
• یک معماری شبکه کانولوشن لیستی از لایه هاست که توده متشکل از تصویر ورودی را به یک توده خروجی ( مثل توده ای که امتیازات دسته ها را در خود دارد) تبدیل میکند.
• تعداد کمی از انواع لایه ها برای شبکه کانولوشن وجود دارد( بعنوان مثال CONV/FC/RELU/POOL متداول ترین لایه ها در شبکه کانولوشن هستند)
• هر لایه یک ورودی سه بعدی را دریافت کرده و انرا از طریق یک تابع مشتق پذیر به یک توده سه بعدی خروجی تبدیل میکند .
• هر لایه ممکن است دارا یا فاقد پارامتر باشد (بعنوان مثال لایه های CONV/FC دارای پارامتر و لایه های RELU/POOL فاقد پارامتر هستند)• هر لایه ممکن است دارا یا فاقد فرا پارامتر(hyperparameter) اضافی باشد. (مثلا لایه های CONV/FC/POOL دارای این نوع پارامترها هستند در حالی که لایه RELU فاقد این نوع پارامتر است)
نمونه ای فعال سازیهای در یک نمونه از معماری شبکه کانولوشن .
توده ابتدایی پیکسل های خام تصویر را در خود ذخیره میکند(تصویر اتومبیل در سمت چپ) و آخرین توده امتیاز دسته ها را در خود جای میدهد(لایه تماما متصل یا به اختصار FC). هر توده فعال سازی در طی مسیر پردازش در قالب یک ستون نمایش داده شده است. از آنجایی که نمایش توده های ۳بعدی مشکل است ما برشهای (قاچهای) هر توده را بصورت سطری مرتب کردیم. توده مربوط به آخرین لایه حاوی امتیازات مربوط به هر دسته (class) است. اما در اینجا ما تنها ۵ امتیاز بالاتر را نمایش دادیم . معماری نمایش داده شده در اینجا یک شبکه VGGNet کوچک است که جلوتر در مورد آن توضیح داده ایم . ما حالا میتوانیم بعد از این آشنایی اولیه , به جزییات بیشتر در رابطه با این لایه ها بپردازیم . در بخش بعد لایه های مختلف و جزییات مربوط به فراپارامترها و اتصالات آنها شرح داده میشوند.
اتمام بخش اول
سید حسین حسن پور
بهار ۹۵
منبع : deeplearning.ir
موضوعات مشابه:
ویرایش توسط Hossein : 15th April 2016 در ساعت 11:47 PM
کلمات کلیدی این موضوع
علاقه مندی ها (Bookmarks)
علاقه مندی ها (Bookmarks)
 مجوز های ارسال و ویرایش
مجوز های ارسال و ویرایش
- شما نمیتوانید موضوع جدیدی ارسال کنید
- شما امکان ارسال پاسخ را ندارید
- شما نمیتوانید فایل پیوست کنید.
- شما نمیتوانید پست های خود را ویرایش کنید
-
مشاهده قوانین
انجمن
Powered by vBulletin
Copyright ©2000 - 2024, Jelsoft Enterprises Ltd.
Content Relevant URLs by vBSEO 3.6.0
Persian Language By Ustmb.ir

این انجمن کاملا مستقل بوده و هیچ ارتباطی با دانشگاه علوم و فنون مازندران و مسئولان آن ندارد..این انجمن و تمامی محتوای تولید شده در آن توسط دانشجویان فعلی و فارغ التحصیل ادوار گذشته این دانشگاه برای استفاده دانشجویان جدید این دانشگاه و جامعه دانشگاهی کشور فراهم شده است.لطفا برای اطلاعات بیشتر در رابطه با ماهیت انجمن با مدیریت انجمن ارتباط برقرار کنید
ساعت 08:18 AM بر حسب GMT +4 می باشد.


 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks










 پاسخ با نقل قول
پاسخ با نقل قول
علاقه مندی ها (Bookmarks)